Samuel Devulder a écrit:
Bon ce soir j'ai trouvé les routines des petits sprites (8x8 : les balles)
Voici la routine, entrecoupée de mes commentaires
Code:
CAB3 3476 PSHS U,Y,X,B,A 13
CAB5 2004 BRA $CABB 3
CAB7 3476 PSHS U,Y,X,B,A 13
CAB9 AE43 LDX $03,U 6
Ah tiens la routine a 2 points d'entrée, l'une prend son paramètre X depuis la structure pointée par U, et l'autre est déjà passée dans le registre X.
Code:
CABB 108E6590 LDY #$6590 4
CABF ECC1 LDD ,U++ 8
CAC1 31A6 LEAY A,Y 5
CAC3 8618 LDA #$18 2
CAC5 3D MUL 11
CAC6 31AB LEAY D,Y 8
Le code au dessus met à jour le pointeur sur les données de sprites (Y). On peut remarquer le "LDD ,U++" peut être remplacé par un "PULU D" qui est plus rapide, et plus globalement si on pouvait passer par un autre registre que Y on gagnerait un peu dans le chargement de l'adresse $6590.
Code:
CAC8 A6C4 LDA ,U 4
CACA 2703 BEQ $CACF 3
CACC 308820 LEAX $20,X 5
CACF 1F23 TFR Y,U 6
Idée: utiliser LEAU ,Y qui est 2 cycles plus rapide que TFR Y,U. Mais aussi on voit que tout le calcul sur Y plus haut dans U. Ca aurait été bien de travailler sur U directement en remontant le test-ci-dessus
avant le calcul en question.
Code:
CAD1 A68810 LDA $10,X 5
CAD4 A4C4 ANDA ,U 4
CAD6 AA80 ORA ,X+ 6
CAD8 A7C4 STA ,U 4
CADA A68810 LDA $10,X 5
CADD A441 ANDA $01,U 5
CADF AA80 ORA ,X+ 6
CAE1 A741 STA $01,U 5
CAE3 A68810 LDA $10,X 5
CAE6 A4C818 ANDA $18,U 5
CAE9 AA80 ORA ,X+ 6
CAEB A7C818 STA $18,U 5
CAEE A68810 LDA $10,X 5
CAF1 A4C819 ANDA $19,U 5
CAF4 AA80 ORA ,X+ 6
CAF6 A7C819 STA $19,U 5
../...
CB6B A68810 LDA $10,X 5
CB6E A4C900A8 ANDA $00A8,U 8
CB72 AA80 ORA ,X+ 6
CB74 A7C900A8 STA $00A8,U 8
CB78 A68810 LDA $10,X 5
CB7B A4C900A9 ANDA $00A9,U 8
CB7F AA80 ORA ,X+ 6
CB81 A7C900A9 STA $00A9,U 8
Bon pas grand chose à dire c'est un découlement du même bloc de masque AND/OR sur 8 lignes écran octet par octet. On doit pouvoir accélérer cela en travaillant sur les registres A et B simultanément (dommage qu'on ait pas de ANDD/ORD). A noter qu'à la fin du déroulement les indexes passent sur 16bits et rend les ANDA/STA très couteux (+3 cycles à chaque calcul d'adresse).
Code:
CB85 3576 PULS A,B,X,Y,U 13
CB87 39 RTS 5
Comme d'habitude on peut fusionner le PULS et le RTS ca fait gagner 3 cycles. C'est pas beaucoup car l'ensemble de cette routine utilise autour de
422 cycles, on gagnerait moins de 1%, mais je pense qu'on peut faire mieux avec le code ci-après qui met en avant ce pourquoi j'utilise un MACRO-ASSEMBLEUR, à savoir les... macros.
Code:
INDEXED MACRO
IFEQ \1
\0 ,\2
ELSE
\0 \1,\2
ENDC
ENDM
Cette macro optimise "OPCODE n,Reg" en "OPCODE ,Reg" quand n=0. Cela va être utile plus loin.
Code:
* sprites 8x8
ORG $CAB3
PSHS D,X,U
BRA L1
PSHS D,X,U
LDX 3,U
L1 LDB #$10
LDA 2,U
BEQ L2
ADDB #$20
L2 ABX
Remarquez ici comment le LEAX 32,X (5 cycles) est transformé en ABX (3 cycles). Le #$10 au début permet d'éviter le passage aux indexes 16 bits plus loin.
Code:
LDD ,U
LDU #$6590+$60 ; début écran de jeu interne
LEAU A,U
LDA #24
MUL
LEAU D,U
Bon là on fait le gros calcul arithmétique directement sur U.
A noter: On ajoute $60 à U pour éviter le passage aux indexes 16 bits dans la routine de masque.
Code:
MSK MACRO
INDEXED LDD,2*\0,X
INDEXED ANDA,24*\0-$60,U
INDEXED ANDB,24*\0-$5F,U
INDEXED ORA,2*\0-16,X
INDEXED ORB,2*\0-15,X
INDEXED STD,24*\0-$60,U
ENDM
MSK 0
MSK 1
MSK 2
MSK 3
MSK 4
MSK 5
MSK 6
MSK 7
PULS D,X,U,PC
Bon là c'est du basic avec la macro. Elle déroule l'algorithme de masquage en faisant en sorte qu'on ait bien un offset 0 (ca fait gagner un cycle, c'est toujours ca de pris) et surtout qu'on reste dans les offset 8 bits (car le passage aux offsets 16 bits est super super pénalisant). Une fois assemblé on obtient:
Code:
CAB3 3456 PSHS U,X,B,A 11 Les deux points d'entrée sont préservés
CAB5 2004 BRA $CABB 3
CAB7 3456 PSHS U,X,B,A 11
CAB9 AE43 LDX $03,U 6
CABB C610 LDB #$10 2 Ajout de 32 à X si le drapeau pointé par U est non nul
CABD A642 LDA $02,U 5
CABF 2702 BEQ $CAC3 3
CAC1 CB20 ADDB #$20 2
CAC3 3A ABX 3
CAC4 ECC4 LDD ,U 5 Calcul de l'adresse d'affichage
CAC6 CE65F0 LDU #$65F0 3 U contient +$60
CAC9 33C6 LEAU A,U 5
CACB 8618 LDA #$18 2
CACD 3D MUL 11
CACE 33CB LEAU D,U 8
CAD0 EC84 LDD ,X 5 Bon 2 octets d'un coup
CAD2 A4C8A0 ANDA $A0,U 5 $A0 c'est -$60 ce qui compense le +$60 en $CAC6
CAD5 E4C8A1 ANDB $A1,U 5 Ca aurait été bien de pouvoir faire un AND direct sur D
CAD8 AA10 ORA -$10,X 5 le -$10 est compensé par le LDB #$10 en $CABB
CADA EA11 ORB -$0F,X 5 Heureux les hc6309 avec leur unité logique 16 bits.
CADC EDC8A0 STD $A0,U 6 Et voilà: on a masqué 2 octets du sprites
../.. (on fait pareil 7 fois)
CB36 EC0E LDD $0E,X 6 Si on avait pas fait +$10 à X, ici on serait en offset 16 bits
CB38 A4C848 ANDA $48,U 5 Grace au +$60, ici on reste sur un offset 8 bits
CB3B E4C849 ANDB $49,U 5
CB3E AA1E ORA -$02,X 5 Ah zut, je loupe le 0,X.. il est utilisé dans le 1er LDD ($CAD0)
CB40 EA1F ORB -$01,X 5
CB42 EDC848 STD $48,U 6
CB45 35D6 PULS A,B,X,U,PC 13
Qui fait 146 octets contre 212 (30% plus court), et s'execute en
300 cycles au lieu des 422, on est
29% plus rapide sur l'affichage des bullets!
Samuel Devulder a écrit:
Peut-être ai-je trouvé des "super boss" de fin de niveaux.. je sais pas.
Ben maintenant je sais

:
Fichier(s) joint(s):
Commentaire: Un méga-boss de fin de niveau en 64x32.
 dcmoto01.png [ 12.37 Kio | Vu 8776 fois ]
dcmoto01.png [ 12.37 Kio | Vu 8776 fois ]
Le boss, que dis-je, le méga-boss de fin de niveau est
ENORME ! Ah, mais j'oublie de signaler qu'en cours de chemin on peut amasser suffisamment de bonus pour que notre propre vaisseau couvre une surface gigantesque. Quand ces deux là se rencontrent, la bataille est épique

Fichier(s) joint(s):
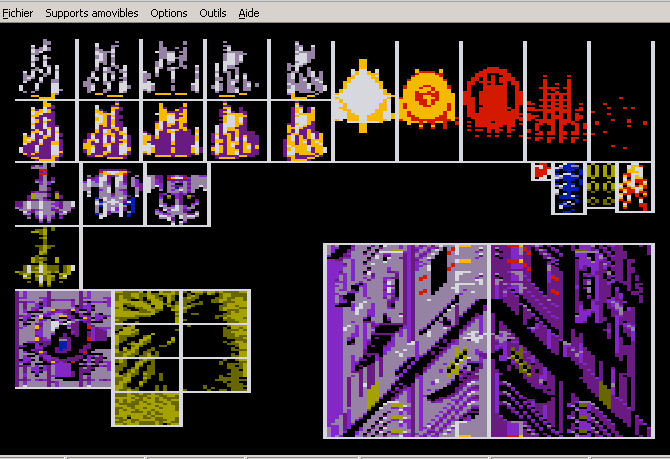
Commentaire: Ouais, ben nous aussi on en a une grosse. Non mais !
 dcmoto03.gif [ 8.66 Kio | Vu 8776 fois ]
dcmoto03.gif [ 8.66 Kio | Vu 8776 fois ]
(bon en vrai on perd super vite notre armement. Il faut tricher)
Note: je n'ai pas encore trouvé la routine pour notre vaisseau amélioré














 essayons de réécrire ceci en optimisant sans se compliquer la vie:
essayons de réécrire ceci en optimisant sans se compliquer la vie: oups.. soporifique.)
oups.. soporifique.) même si il me faut plus de temps pour comprendre, faut laisser reposer pour assimiler
même si il me faut plus de temps pour comprendre, faut laisser reposer pour assimiler {kind=link}
{kind=link}
{kind=link}